Lirot.ai Benchmarked Against Expert Ophthalmologists for Referable Eye Disease Detection
- Joachim Behar
- Jun 9
- 5 min read

Updated: Jun 25
Publication URL: https://iopscience.iop.org/article/10.1088/3049-477X/ae81b9
Authors: Renee Najman, Ben Gofrit, Benjamin Cohen, Or Abramovich, Meishar Meisel, Meital Baskin, Joel Hanhart, Fernando Malerbi, Assaf Kratz, Michael Waisbourd, Ari Leshno, Hadas Pizem, Dinah Zur, Nitsan Duvdevan-Strier, Luis Nakayama, Eran Berkowitz, and Joachim A. Behar
We are pleased to share that our lab’s paper, “Benchmarking Lirot.ai Against Expert Ophthalmologists for Clinical Detection of Referable Eye Diseases,” has been published in IOP Machine Learning: Health.
The study evaluates Lirot.ai, an AI system developed for retinal image analysis, against expert ophthalmologists in the detection of three major vision-threatening eye diseases from color fundus images: glaucomatous optic neuropathy (GON), referable age-related macular degeneration (rAMD), and referable diabetic retinopathy (rDR).
These diseases are among the leading causes of preventable vision loss. Early detection is critical, but screening programs face a practical challenge: there are not enough specialists to manually review every image at scale. This creates an urgent need for AI systems that are not only accurate, but also trustworthy, clinically useful, and robust in realistic screening conditions.
Why this study matters
Many AI models for retinal imaging have shown strong results on retrospective datasets. However, clinical adoption requires more than good benchmark scores. AI systems need to be compared against human experts, tested on data from settings they have not seen during training, and evaluated under conditions that resemble real-world screening.
In this study, we asked a simple but important question:
How does Lirot.ai perform compared with experienced ophthalmologists when both are asked to detect referable eye disease from a single non-mydriatic digital fundus image?
To answer this, we conducted a remote, masked reader study involving 10 ophthalmologists from eight medical institutions in Israel and Brazil. Most readers were senior specialists, and most had at least six years of clinical experience. Each reader independently graded the same set of 91 fundus images, without access to patient demographics, clinical history, or Lirot.ai outputs.
The dataset included 55 referable disease images and 36 non-referable or control images, spanning GON, rAMD, rDR, early-stage disease, and none-of-the-above controls. Ground-truth labels were based on comprehensive ophthalmic examinations and follow-up.
| Years of experience | |||
Training level | Subspecialty | 0-5 | 6-10 | 11+ |
Resident | | 1 | | |
Sr Ophthalmologist | Glaucoma | 1 | | 2 |
Neuro-ophthalmology | | | 1 | |
Retina | | 1 | 3 | |
Fellow | | | 1 | |
Table: Readers.
Key findings
Lirot.ai demonstrated strong performance across all three target diseases.
For glaucomatous optic neuropathy, Lirot.ai achieved an AUROC of 0.860, with sensitivity of 88.2% and specificity of 74.3% at the operating point selected by Youden’s Index. This was the most striking result: human readers detected GON with substantially lower sensitivity on average.
For referable AMD, Lirot.ai achieved an AUROC of approximately 0.923, with sensitivity of 92.9% and specificity of 89.6%.
For referable diabetic retinopathy, Lirot.ai achieved an AUROC of 0.954, with sensitivity of 91.7% and specificity of 94.0%.
Across the three diseases, Lirot.ai reached the highest sensitivity among readers while maintaining specificity within the range of human expert performance. In practical terms, this means that Lirot.ai was particularly effective at capturing patients who may require referral, while still maintaining a clinically meaningful false-positive rate.

Figure: Lirot.ai performance. Lirot.ai GON (A), rAMD (B), and rDR (C) sensitivity and specificity as compared to ten expert readers’ sensitivity-specificity detection performance for each condition. Reader points to the left, in-line, and right of the curve represent scores better-than, on-par with, and less than Lirot.ai with Lirot.ai outperforming human readers for glaucoma detection (A) and performing on-par with human readers for rAMD (B) and rDR (C) detection. While the entire curve is representative of model performance, Youden’s J, an optimal balance of sensitivity and specificity, is demarcated for each condition.

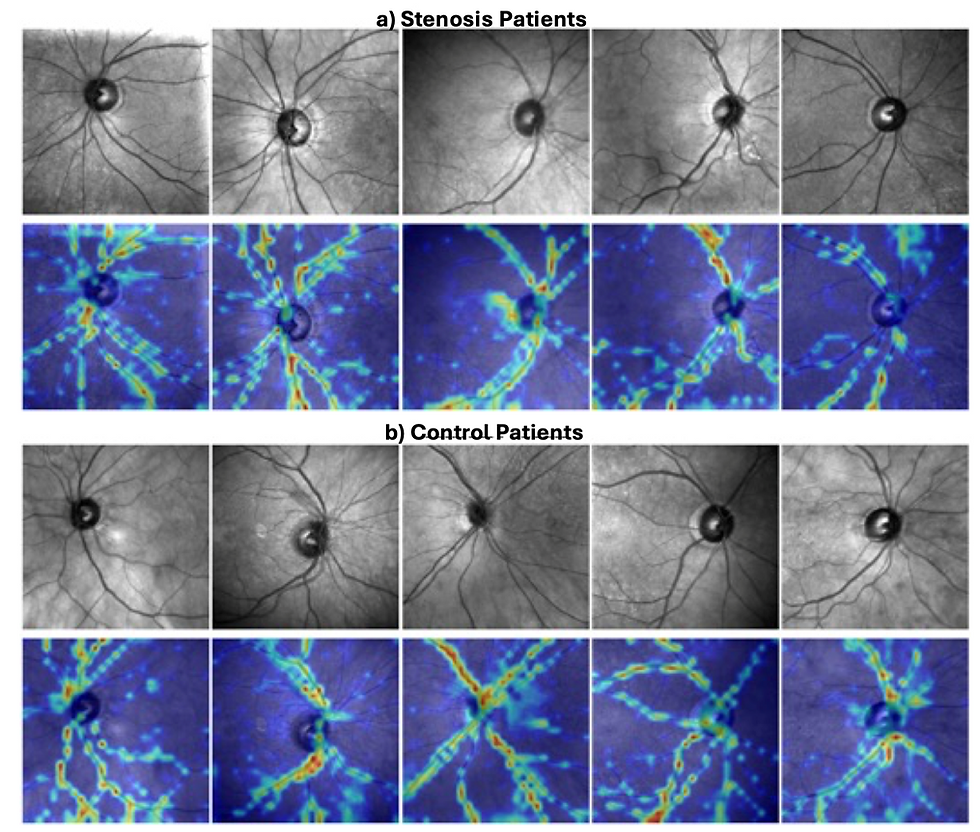
Figure: Explainability maps. Heat maps of areas attended to by Lirot.ai in its inference of these samples as GON, rAMD, and rDR can be observed in panels A, B, and C, respectively. Upper level is the original image and lower level is the complementary attention map.
A complementary role for clinicians and AI
One of the most interesting observations was the difference in sensitivity-specificity tradeoff between Lirot.ai and the ophthalmologists.
Human readers tended to show higher specificity, meaning they produced fewer false positives. Lirot.ai tended to show higher sensitivity, meaning it captured more referable cases. This suggests a natural clinical workflow: Lirot.ai can serve as a high-sensitivity triage or screening tool, flagging suspicious cases for expert review, while clinicians remain central to final interpretation and patient management.
This is especially relevant for glaucoma. Glaucoma can be difficult to detect from a single fundus image and is often asymptomatic in early stages. In the study, inter-reader agreement for GON was lower than for rAMD and rDR, reflecting the difficulty of the task. Lirot.ai’s improved sensitivity in this setting may therefore offer important added value for screening programs.
Robustness on challenging images
The study also examined images that human readers marked as ungradable or of insufficient quality. Among images marked ungradable by at least two readers, Lirot.ai correctly classified 11 of 14 cases. Its performance on these challenging images remained substantially stronger than the average human-reader performance in that subset.
This finding is encouraging because real-world screening rarely involves perfect images. Blur, artifacts, media opacity, and variable acquisition quality are common in practice. A screening tool that remains useful under imperfect conditions could help reduce missed referrals and improve access to care.
Speed and scalability
The time difference between human and AI interpretation was also substantial. Human readers took, on average, between 12.3 and 30.2 seconds per image. Lirot.ai processed each image in approximately 0.0425 seconds on an A100 GPU.
This does not mean that AI replaces clinicians. Rather, it highlights the potential of AI to support high-throughput screening workflows, especially in settings where ophthalmology resources are limited. By rapidly identifying images that warrant attention, Lirot.ai could help specialists focus their time where it is most needed.
Comparison with foundation models
The study also compared Lirot.ai with two visual-language foundation models, MedGemma4B and EyeCLIP, in a zero-shot setting. These models did not perform reliably across the multi-disease screening task. Some outputs reflected extreme behavior, such as classifying nearly all cases as negative for a disease or nearly all cases as positive.
This result reinforces an important message: general-purpose or broad medical foundation models are not automatically ready for clinical screening tasks. Disease-specific validation, clinically meaningful thresholds, and out-of-domain testing remain essential.
What comes next
The study positions Lirot.ai as a promising AI copilot for retinal disease screening, particularly for detecting referable GON, rAMD, and rDR from fundus images. At the same time, we are careful to frame this as an important validation step rather than a final claim of autonomous clinical deployment.
Future work should include larger, prospective, multi-site studies with more diverse populations, imaging devices, disease combinations, and real-world screening conditions. Such studies will be essential for evaluating generalizability, workflow integration, safety, and clinical impact.
Looking ahead
This work reflects the broader mission of our lab: developing AI tools that are not only technically strong, but clinically meaningful, interpretable, and useful in real healthcare pathways.
Lirot.ai’s performance in this study suggests that AI can help expand access to high-quality retinal screening, reduce the burden on specialist readers, and support earlier detection of diseases that threaten vision.
We congratulate all collaborators involved in this work and look forward to the next steps in translating Lirot.ai toward broader clinical impact.


This is a very informative and easy-to-understand article about retinal detachment. The explanation of symptoms, causes, and the importance of seeking prompt medical attention is especially helpful. Many people may not recognise the warning signs, so educating readers like this can make a real difference. Anyone researching Retinal Detachment Treatment in Utah can benefit from understanding the condition better.